Center for Big Data Computing
About
Center for Big Data Computing was established in the year 2016, with a mission of creating a tech innovation ecosystem on cutting edge technologies from diverse communities against the requirement of complex real world challenges. Data science is the process of using algorithms, methods and systems to extract knowledge and insights from structured and unstructured big data. It provides an extensive computing platform that provide complete and generic solution to data handling problems posed by big data and data science lifecycle - from preparing and exploring data to building, deploying, managing and monitoring models.
B2DC is actively involved in theoretical and applied research in the broad areas of Big Data, Predictive Analytics, Machine Learning, Data Visualization, Natural Language Processing, cloud computing and Internet of Things (IoT). The center focus on solving real-world challenges by utilising Big Data and Data Science technologies through extensive academic research of faculty, research scholars, post graduate and under graduate students to accelerate the implementation of solutions.
The primary functions of the research centre are to
- Provide excellent research culture and infrastructure.
- Serve as a platform for strong interdisciplinary collaborations and knowledge sharing.
- Publish papers in high quality journals of international repute.
- Create quality human resources for scientific research.
- Promote industrial collaborations involving active and mutually beneficial R & D projects.
- Understanding of technology transfer processes and practices that lead to successful commercialization
Key features of the space include:
Big Data Technology – these facilities enable the students to understand the distributed environment and working with NoSQL databases on Hadoop technology stack to enhance the employment opportunities.
Cloud Computing – rovide the extended infra structure in cloud environment on Aneka, Microsoft Azure, OpenNebula for building, testing, deploying, and managing applications and services and IBM Bluemix to provide edge computing
Data Science - Provides tools and technologies used for Advanced analytics to extract knowledge and insights from structured and unstructured data.
MAJOR EQUIPMENT
Big Data Technologies
Big data framework having a fully functional practice of Hadoop distributed environment with a technology stack of Apache Spark, Apache Flink, Apache Pig, Apache Hive, Apache Kafka, MongoDB, Apache Mahout, Cassandra, etc. and emerging open source technologies to deliver robust business results.
Hardware facilities:
- 30 Numbers of High configuration systems (Intel core i7 processor, 16 GB RAM, 2TB HDD)
- 2 Power edge Servers (Power Edge R730 Sever BLAD)
Software available:
| Software |
Description |
 |
Hadoop framework allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is essential for working with data science projects. |
 |
Oracle is enterprise database used for running online transaction processing, data warehousing and mixed database workloads. It provides Database Enterprise Edition Database Options: Real Application Clusters, Oracle Spatial and Graph Enterprise Management: Database Lifecycle Management Pack, Oracle Diagnostics Pack, Oracle Tuning Pack Big Data: No SQL Database Enterprise Edition Data Warehousing: Advanced Analytics Oracle Middleware Licensed Products Cloud Application Foundation: Web Logic Suite Data Integration: Data Integrator Enterprise Edition Service Oriented Architecture: SOA Suite for Oracle Middleware Web Center: Web Center Suite Plus Business Intelligence: Business Intelligence Suite Enterprise Edition Plus, Essbase Plus Identity Management: Identity Manager Business Process Management: Unified Business Process Management Suite Developer Suite: Top Link and Application Development Framework |
| Purpose |
Academic and Research |
| Cost |
Rs. 12,52,267/- |
| Location and Hours |
First Floor 1015, Aryabatta Block, 09:30 AM - 06:00 PM |
Cloud Computing)
Cloud computing environment provides collection of virtual resources such as software development kit, rapid application development and deployment and edge computing environments for distributed analytics and real time big data analytics.
| Software |
Description |
 |
Aneka is a platform and a framework for developing distributed applications on the Cloud. It is a collection of physical and virtualized resources connected through a network, which are either the Internet or a private intranet. It provides: Software Development Kit (SDK) - a combination of APIs and Tools to build different run-time environments and new applications. Rapid Development and Deployment of Applications in Multiple Run-Time environments. Graphical User Interface (GUI) and APIs to set-up, monitor, manage and maintain remote and global Aneka compute clouds. |
 |
OpenNebula, the Cloud & Edge Computing Platform. It is used for creating a distributed system services and applications. |
 |
Microsoft Azure is a cloud computing service. It is used for building, testing, deploying, and managing applications and services through Microsoft-managed data centres. It helps to create cloud-based resources, such as virtual machines (VM) and databases. The services provided for distributed analytics and storage such as features for real-time analytics, big data analytics, data lakes, machine learning (ML), business intelligence (BI), internet of things (IoT) data streams and data warehousing. |
| Purpose |
Academic and Research |
| Cost |
Rs. 24,46,860/- |
| Location and Hours |
First Floor 1014, Aryabatta Block, 09:30 AM - 06:00 PM |
Data Science
Across sectors and businesses, data science has established itself as a pre-requisite for developing effective data-driven decisions and insightful business strategies. The tools and technologies used to extract knowledge and insights from structured and unstructured data. The Data Science Lab focuses on applying machine learning, data mining, and network analysis to real-world problems in society and industry. It provides learning and working on Applied Machine Learning, Complex Networks Analysis, visualizations and Business Intelligence.
| Software |
Description |

IBM SPSS Modeler Server & Client – Clementine |
SPSS Modeler is used to visual data science and machine-learning solution. It includes data preparation and discovery, predictive analytics, model management and deployment, and machine learning to monetize data assets. It helps to create data assets and modern applications, with complete algorithms and models that are ready for immediate use. |

Business Intelligence Sooftware – Tabuleau |
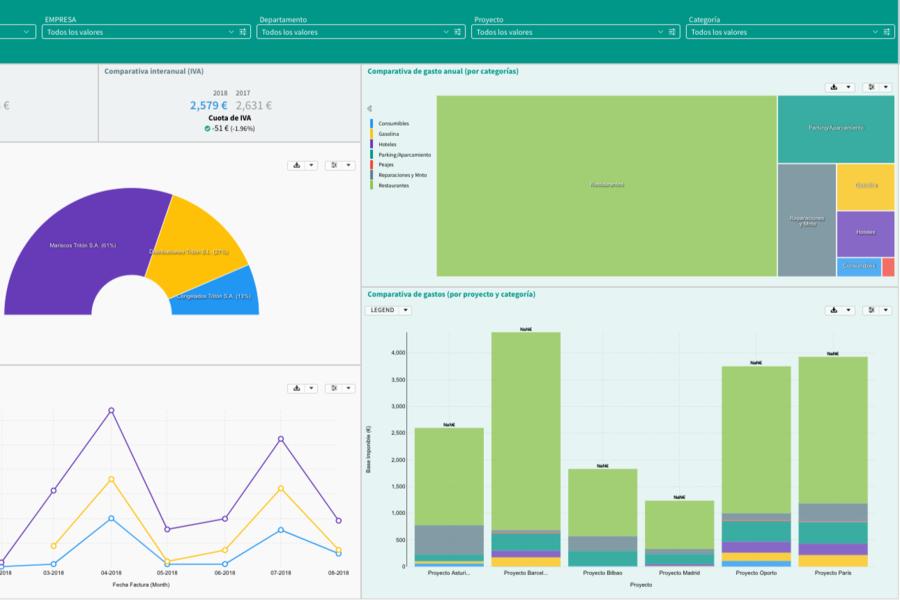
Tabuleau is a data visualization and analysis platform. It used as business-expert oriented tool and fully customized information is presented through interactive dashboards and reports. Tabulae provides dynamic operating mechanisms, enriching both user experience and the user's ability to interpret data. |
| Purpose |
Experiential Learning and Research |
| Cost |
Rs. 9,41,395/- |
| Location and Hours |
First Floor 2104, Abdul Kalam Block, 09:30 AM - 06:00 PM |
Contact
Dr. M Madhu Bala
Professor of Computer Science and Engineering
Email: m.madhubala@iare.ac.in
Phone: 9885543778